64 docs indexed
Fairshare Engine
How obleth's admission scheduler chooses slots under saturation across weighted and hierarchical fairshare.
The fairshare engine is obleth's heart. It answers one question: when the cluster is at capacity and a new request arrives, which tenant's queued request gets admitted next?
Admission model
Every open slot is assigned deliberately.
A single scheduler owns queue order and in-flight counts. This example shows two tenants competing for an eight-slot pool: chatbot has weight 500, while api-batch has weight 50.
Admit
obleth identifies the tenant and policy before routing upstream.
Queue
When the pool is full, requests wait by tenant instead of racing.
Pick
The next open slot goes to the tenant most entitled to it.
Release
The slot returns when the model response finishes streaming.
Hierarchical mode - current runtime default
Group caps keep api-batch alive under a 10x weight gap.
With an eight-slot pool and active groups weighted 500:50, the gateway allocates seven slots to chatbot and one reserved slot to the api group. api-batch still queues, but it does not vanish.
chatbot
group chatbot / weight 500
cap 7 / queued 57
api-batch
group api / weight 50
cap 1 / queued 31
8-slot pool
example split
Inside a group
Each group gets its own fairshare queue.
After group caps reserve capacity, tenants inside the eligible group are balanced by how much work they have already received. A busy tenant cannot permanently crowd out its peers.
chatbot
served 8.6k
queued 28
ahead
chatbot-2
served 8.4k
queued 29
next
batch-job
served 9.1k
queued 12
waits
Fast
If capacity is open and no backlog exists, the request is admitted immediately.
Queued
If the pool is full, the request waits until a released permit triggers dispatch.
Rejected
Only when a hard limit is crossed — the per-minute token budget (429) or a term budget (403).
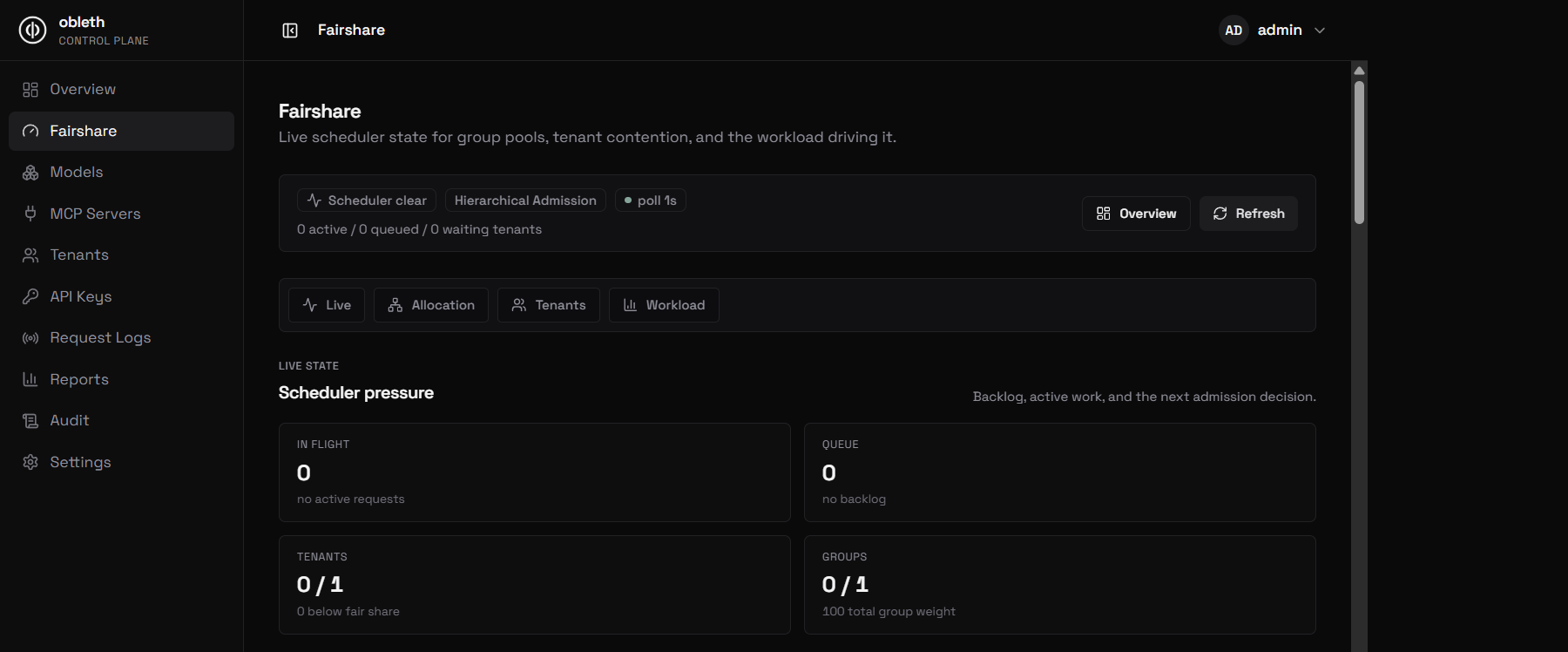
The Fairshare page in the control plane visualizes this live: scheduler pressure (in-flight, queue depth, tenants below fair share, group pools) updates on a one-second poll so you can watch admission decisions as they happen.
Core idea
Under the flat weighted algorithm, each tenant accumulates a served counter in tokens as requests are admitted. The scheduler tracks the ratio served / weight for every active tenant. When a slot opens, it goes to the tenant with the lowest ratio — the one most behind its proportional fair share.
A tenant with weight=500 gets roughly ten times the throughput of one with weight=50, not by receiving ten times more slots, but because the scheduler always picks the most under-served tenant next.
Two algorithms
Weighted
All tenants compete globally. Admission scores are served_tokens / weight. The tenant with the lowest score wins each slot.
This is start-time fair queuing (STFQ) applied to token cost: a tenant that just used a lot of tokens won't be selected again until the others catch up relative to their weights.
Set with OBLETH_FAIRSHARE_ALGORITHM=weighted.
Hierarchical (current runtime default)
Global capacity is first partitioned among fairshare groups by group weight, then split evenly among tenants within each group.
For example, with OBLETH_GLOBAL_MAX_IN_FLIGHT=8 and two groups:
prodgroup (weight 500) → ~7 slotsdevgroup (weight 50) → ~1 slot
Within each group, slots are distributed evenly regardless of individual tenant weights. This lets you protect an entire team or product category as a unit.
Set with OBLETH_FAIRSHARE_ALGORITHM=hierarchical.
The single-scheduler design
A single Tokio async task owns all admission state. All requests send an Admit message and receive a Permit back. There are no locks on the hot path, no races between concurrent admission decisions, and the scheduler's view of in-flight counts is always consistent.
The permit is a Rust RAII type: dropping it automatically sends a Release message to the scheduler, freeing the slot. This means the slot is held for the full duration of the upstream call including streaming time. Concurrency accounting reflects real GPU occupancy.
Priority boosts
Because tenant weight is just a field in Postgres and Redis, changing it takes effect on the next admission decision after the cache is invalidated. You don't need to restart obleth or reload config.
# Double the chatbot's priority during a traffic spike
curl -X PATCH http://localhost:9180/api/v1/tenants/$TID/weight \
-H "Authorization: Bearer $TOKEN" \
-H "Content-Type: application/json" \
-d '{"weight": 1000}'
The pub/sub invalidation channel propagates the change to every gateway pod's moka cache within milliseconds.
Starvation-free guarantee
Fairshare admission via share_score means no tenant with non-zero weight can be starved indefinitely. A low-weight tenant's score grows more slowly per token served than a high-weight tenant's, but it always advances while it is active. When a heavy tenant's score catches up, the light tenant becomes the most behind fair share and receives the next slot.
The scheduler implements a DRR-inspired policy; see DRR Algorithm for the mapping between classic deficit counters and share_score.
Idle tenants don't accumulate "credit" they can spend in a burst — the scheduler resets the served counter context so they can't coast on historical inactivity.
Queue, don't reject
When the cluster is at capacity, a new request is admitted with Admission::Queued and waits for a permit to free up rather than failing at the door. It keeps its place until the scheduler selects it — there is no timeout that shortens or drops the request. obleth only returns an error when a hard limit is crossed: a 429 when the per-minute token budget is empty, or a 403 when a term budget is exhausted.
See Saturation Behavior for the full set of outcomes under load.
Live fairshare state
The Management API exposes a real-time snapshot of the scheduler:
curl http://localhost:9180/api/v1/fairshare/live \
-H "Authorization: Bearer $TOKEN"
Returns per-tenant and per-group in_flight, queued, served_tokens, share_score, and weight_share — exactly what the control-plane dashboard displays.