64 docs indexed
Quotas & Rate Limits
How to configure tokens_per_minute (TPM) and per-tenant max_in_flight caps, and what each one controls.
obleth has two independent throttling mechanisms per tenant: a token budget (TPM) and an optional concurrency cap (max_in_flight). They operate at different layers and can be used together.
Both are set per tenant from the dashboard on the Tenants → Controls tab, under Safety limits — or via the Management API shown below:
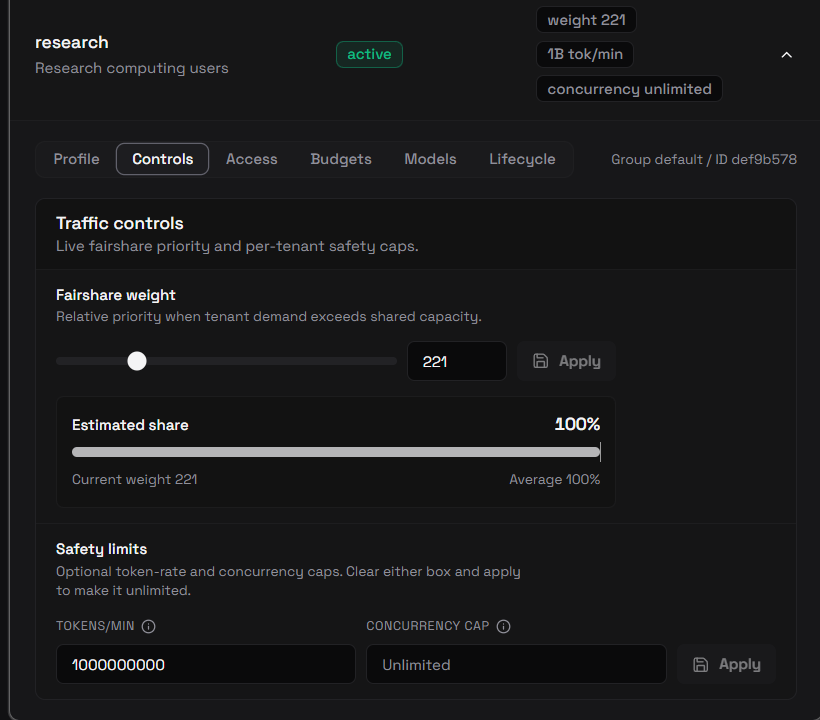
Token budget (tokens_per_minute)
tokens_per_minute is a token-bucket rate limit. It controls how many tokens a tenant can consume in a sustained period.
Token bucket mechanics:
- Capacity (burst ceiling) =
tokens_per_minute - Refill rate =
tokens_per_minute / 60000tokens per millisecond - A tenant that's been idle can consume up to
tokens_per_minutetokens in a single burst - After the burst, the bucket refills at the sustained rate
When the bucket is empty, the next request that would exceed it gets 429 token budget exceeded. The fairshare permit is released and the request is not proxied.
Setting TPM at creation
curl -X POST http://localhost:9180/api/v1/tenants \
-H "Authorization: Bearer $TOKEN" \
-H "Content-Type: application/json" \
-d '{
"name": "chatbot",
"weight": 500,
"tokens_per_minute": 2000000
}'
Updating TPM
curl -X PUT http://localhost:9180/api/v1/tenants/$TID/quota \
-H "Authorization: Bearer $TOKEN" \
-H "Content-Type: application/json" \
-d '{
"tokens_per_minute": 5000000,
"max_in_flight": null
}'
TPM sizing guidance
| Use case | Suggested TPM |
|---|---|
| Internal dev/test tenant | 50,000–200,000 |
| Single chat user | 100,000–500,000 |
| Production chatbot service | 1,000,000–5,000,000 |
| Batch processing job | 500,000–2,000,000 |
A 70B model at typical throughput consumes ~1,000–3,000 tokens/second per concurrent request.
Per-tenant concurrency cap (max_in_flight)
max_in_flight is an optional hard cap on how many requests a single tenant can have in flight simultaneously, regardless of the global limit.
With max_in_flight=null (default), a tenant is only constrained by the global OBLETH_GLOBAL_MAX_IN_FLIGHT and the fairshare scheduler. Setting it adds an additional per-tenant ceiling.
When to use max_in_flight
- Protect backends from tenant bursts: a batch job might have a very high TPM budget but shouldn't hold more than 10 concurrent slots.
- Enforce priority tiers: a low-priority tenant capped at 2 concurrent requests vs a high-priority tenant at 20.
- Debug a misbehaving client: temporarily cap a tenant at 1 while investigating.
Setting max_in_flight
curl -X PUT http://localhost:9180/api/v1/tenants/$TID/quota \
-H "Authorization: Bearer $TOKEN" \
-H "Content-Type: application/json" \
-d '{
"tokens_per_minute": 2000000,
"max_in_flight": 10
}'
Remove the cap:
curl -X PUT http://localhost:9180/api/v1/tenants/$TID/quota \
-H "Authorization: Bearer $TOKEN" \
-H "Content-Type: application/json" \
-d '{"tokens_per_minute": 2000000, "max_in_flight": null}'
Term budgets (cumulative caps)
tokens_per_minute is a rate limit; a term budget is a cumulative cap on
how much a tenant may consume over a longer period. It is independent of the
per-minute bucket and is the right tool for a monthly spend ceiling or a fixed
trial allowance.
A term budget has three parts:
| Field | Purpose |
|---|---|
budget_tokens | Optional cap on total tokens for the period. |
budget_cost_usd | Optional cap on total USD cost (using per-model pricing) for the period. |
budget_period | lifetime, monthly, or term. monthly rolls over each calendar month; term resets when you change the budget; lifetime never resets. |
Either cap (or both) may be set. When usage for the current period meets either
cap, the data plane returns 403 tenant term budget exhausted until the period
rolls over or you raise the cap. obleth tracks period usage in Redis
(obleth:term_usage:{tenant}) and reconciles real cost after each stream.
# Cap a trial tenant at 50M tokens and $250 per month
curl -X PATCH http://localhost:9180/api/v1/tenants/$TID/budget \
-H "Authorization: Bearer $TOKEN" \
-H "Content-Type: application/json" \
-d '{
"budget_tokens": 50000000,
"budget_cost_usd": 250.0,
"budget_period": "monthly"
}'
How the limits interact
The limits are enforced independently, at different layers. A request can be held or rejected by any of them:
| Check | Where | Outcome if exceeded |
|---|---|---|
| Global concurrency | Fairshare scheduler | Queued (admitted later) |
Per-tenant max_in_flight | Fairshare scheduler | Queued (admitted later) |
Token budget (tokens_per_minute) | Redis Lua | 429 token budget exceeded |
Term budget (budget_tokens / budget_cost_usd) | Redis | 403 tenant term budget exhausted |
Concurrency limits queue the request (it may be admitted later); the TPM and term budgets are hard rejections.
Monitoring quota utilization
Query ClickHouse for TPM utilization per tenant:
SELECT
tenant_id,
sum(input_tokens + output_tokens) AS tokens_used,
count() AS requests,
countIf(admission = 'rejected') AS rejected
FROM usage
WHERE ts_ms > (toUnixTimestamp(now() - INTERVAL 1 HOUR) * 1000)
GROUP BY tenant_id
ORDER BY tokens_used DESC
Or use the Management API:
curl "http://localhost:9180/api/v1/usage?since_ms=$(date -d '1 hour ago' +%s000)" \
-H "Authorization: Bearer $TOKEN" | jq .